Don’t trust the magazines on choosing an OCR
This covidiocy is so alienating that I wasn’t in the mood of writing anything. Better late than never, a few notes on the free OCR software, simply because a stupid British magazine pissed me off.
There is this thing called Web User Magazine, belonging to Penis Publishing (that’s a cheap one, I know), and they recently included a short roundup on “Best free OCR software”:

That’s bollocks. There’s absolutely nothing worth mentioning in their selection. Guaranteed crap. But what OCR should one choose instead?
In the past, I used to swear by ABBYY FineReader, but they didn’t seem to be able to progress: in all the versions I tried (from 9.0 to 15.0), no matter I was selecting the proper language dictionary, all the Romanian words that started with “Δ (at the beginning of a phrase) were identified as starting with “î”. Occasionally, there were other misidentifications that I judged unacceptable for a commercial solution that included a dictionary for the recognized language, and that was fed with good quality images. So I dropped ABBY once and for all.
To the point: what you need to use is tesseract, still the best OCR there is, free, open-source, and able to use dictionaries for most languages. Nothing is perfect on Earth, but for OCR you don’t need to look farther than that. (Alpha builds of version 5.0 for Windows are provided by Universitätsbibliothek Mannheim; make sure you install the additional language data!)
Well, you still have though: unless you love to use the command line for everything, you should be looking for a GUI front-end.
■For Android, there’s Text Fairy, an app that uses Tesseract and works fabulously well (just make sure you select the correct language). And it too is open-source.
■For Windows and Linux, the GUI of choice is gImageReader. It provides Qt-based binaries for Windows (e.g. gImageReader_3.3.1_qt5_x86_64.exe), and mentions that builds exist at least for Debian, Fedora, Ubuntu (PPA), OpenSUSE, Arch Linux. Generally, the Linux GUI is using Gtk+, and it’s called “gimagereader” (very rarely “gimagereader-gtk”); the Qt-based “gimagereader-qt” only exists for Fedora, ALT and Arch.
Using the Windows version is simple, except for an initial hiccup that should happen on most systems:
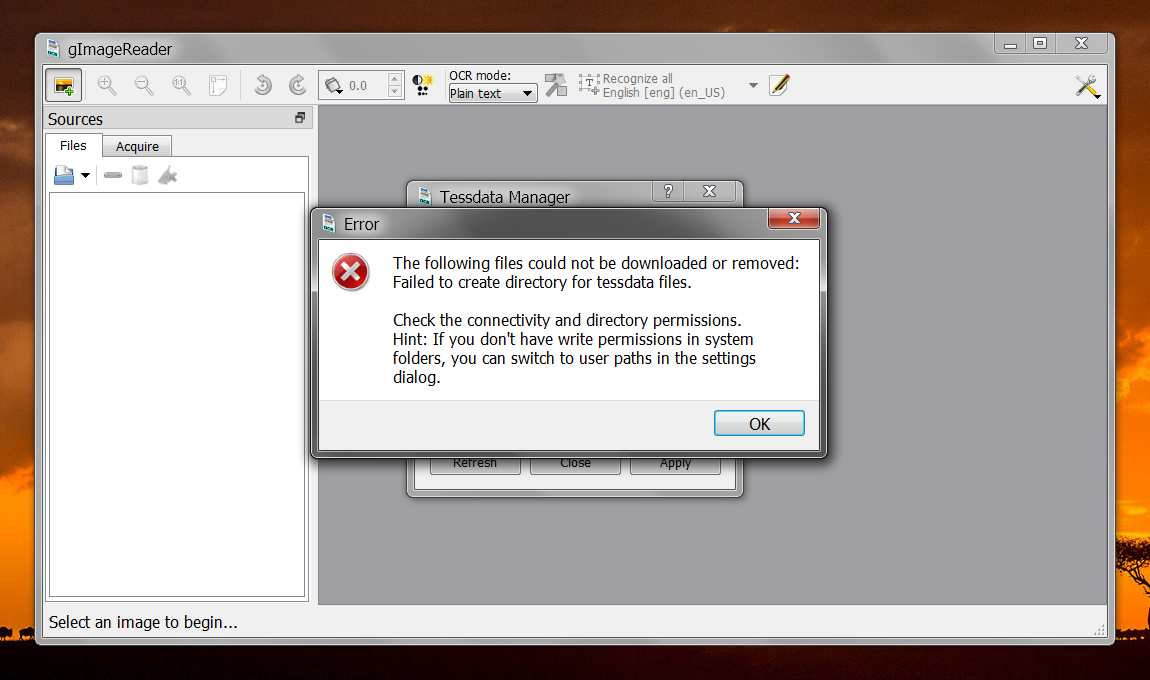
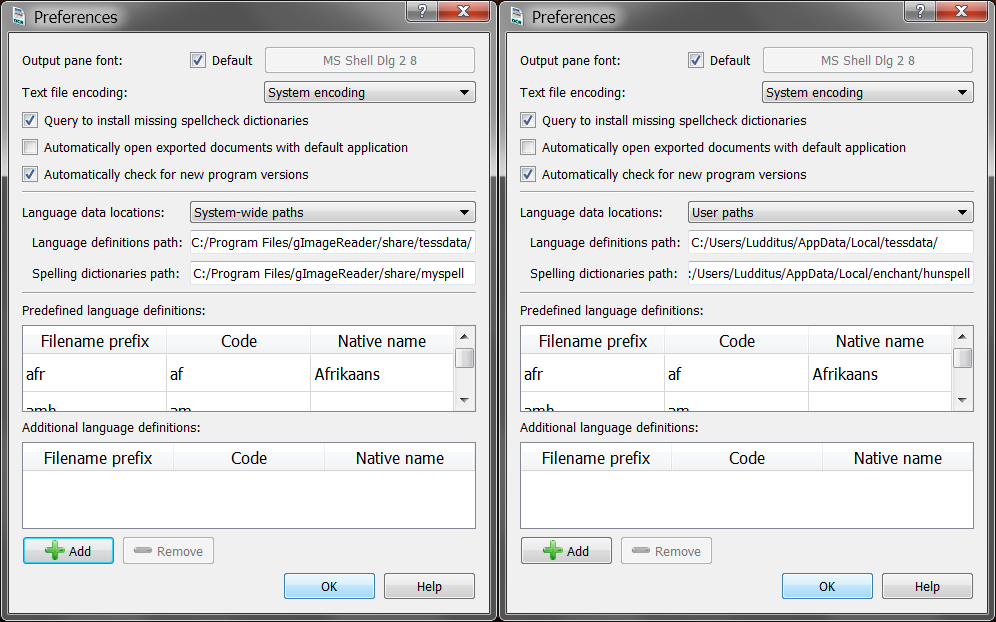
It tries to download Tesseract’s language data in a folder in Program Files, and no non-elevated program has this right–it’s like this since Vista. So we need to change the language data location from “System-wide paths” to “User paths”:
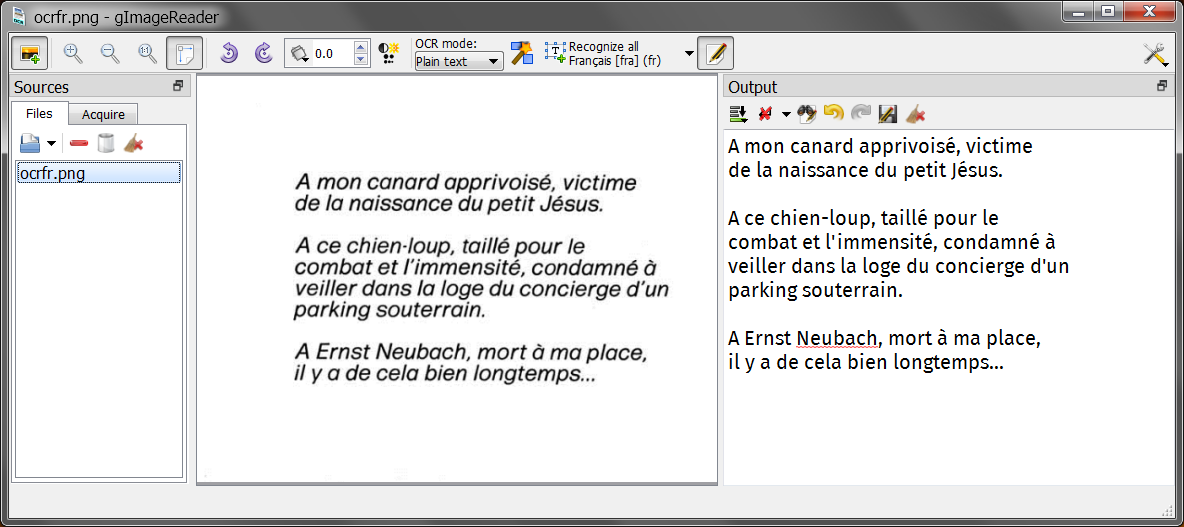
After downloading the languages for the text to be recognized, everything should work rather smoothly:
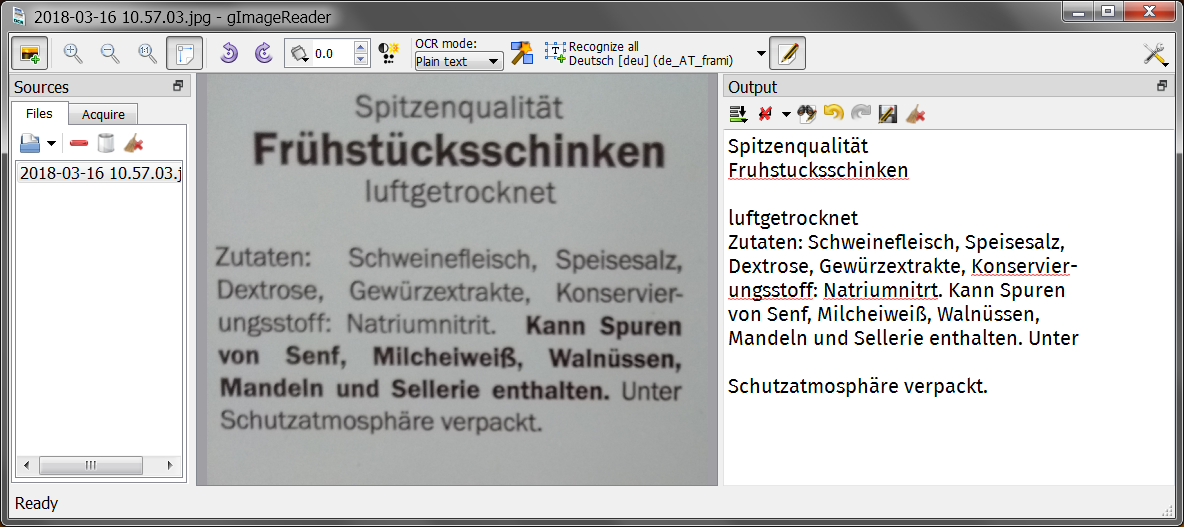
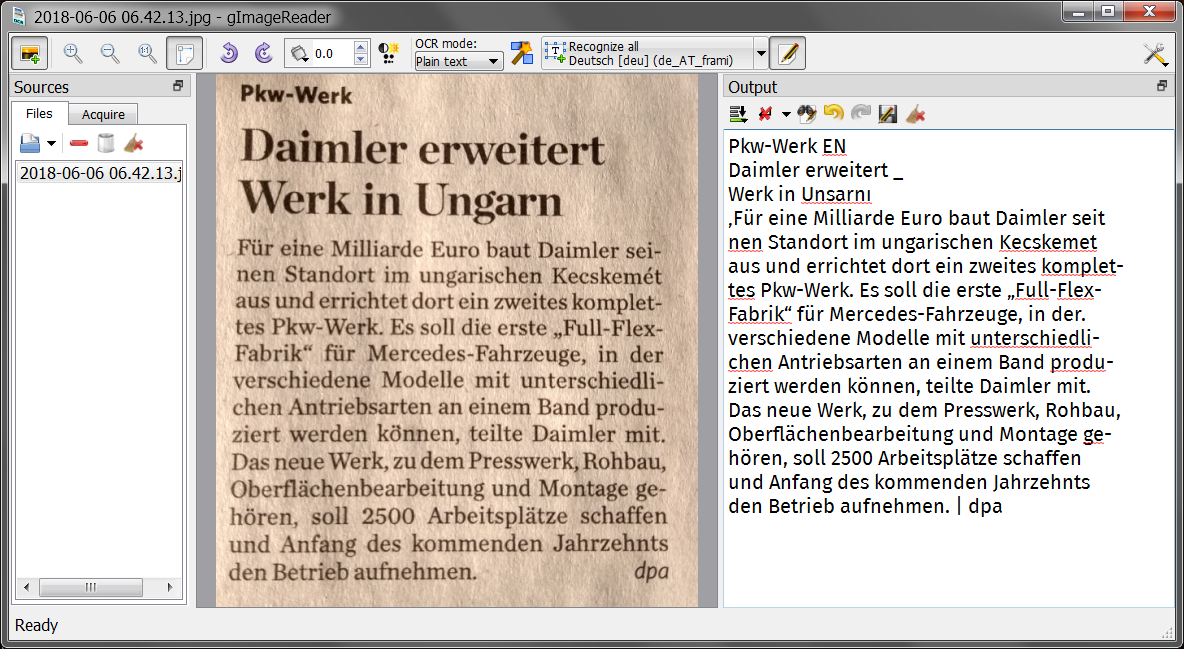
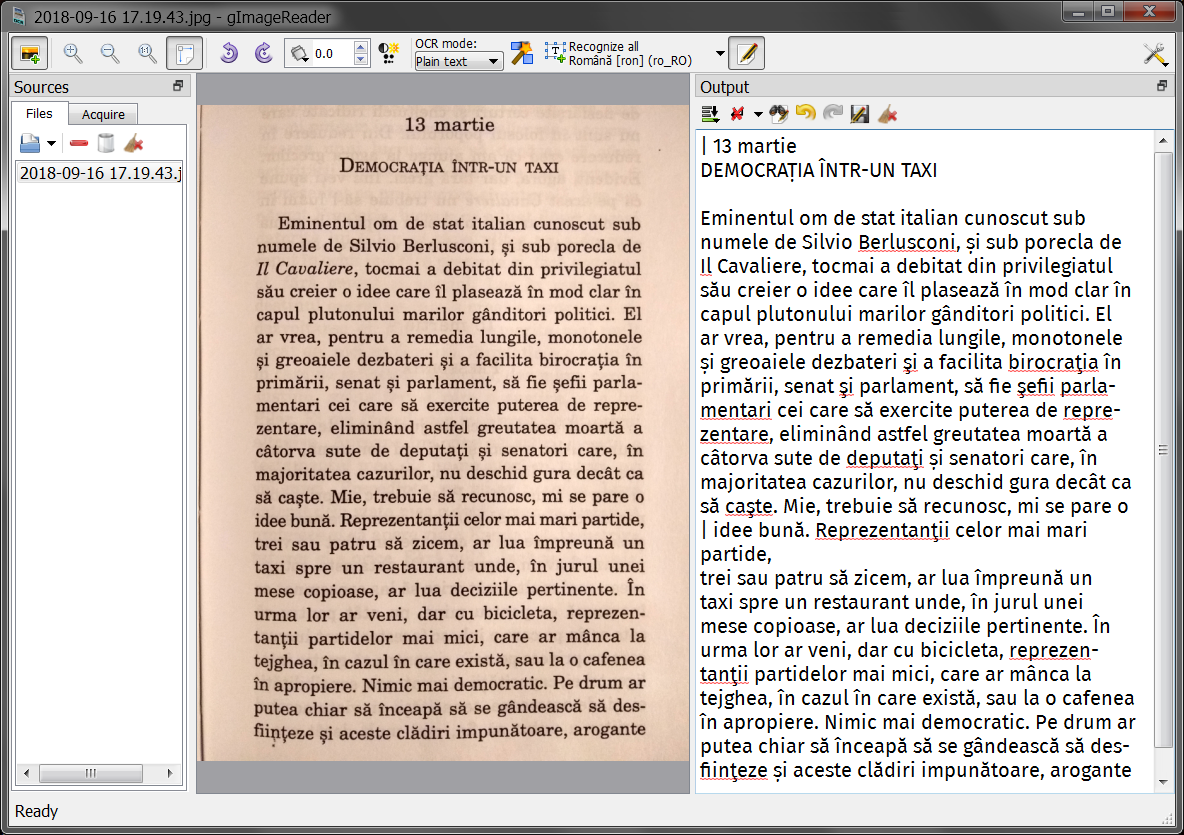
There’s a small annoyance for Romanian though: the recognition uses “ţ” (U+0163, t with cedilla), whereas the dictionary-based spelling checker checks against the correct Romanian character “ț” (U+021B, t with comma below). The same for “ş” (U+015F, s with cedilla) instead of the correct “ș” (U+0219, s with comma below). This used to be a problem with Microsoft’s fonts and keyboard layouts prior to XP SP3, but it seems to have a second life even in the Open Source world.
As a matter of fact, the so-called “Romanian (Germany)” layout, which adds the Romanian characters to a German keyboard is using the wrong characters (i.e. with cedilla) even in the last version of xkeyboard-config. Here, in the symbols/de file:

Most Romanians are idiots who couldn’t care less about their language: they never cared to use the proper characters while using a computer; I believe they’re the only country on Earth where the physical keyboards that can be purchased don’t have the specific characters (șțîă) painted on them, but they’re actually either US International or UK keyboards! Try to do this in Poland (ąćęłńóśźż) or in Hungary (áéíóöőúüű)!
In Linux, one should install gimagereader from the official repositories of their distro, and the required dependencies should be retrieved too. Attention though! Tesseract’s language files are not automatically added as dependencies, so one should either install tesseract-ocr-all, or pick only the needed languages (e.g. tesseract-ocr-deu, tesseract-ocr-fra, tesseract-ocr-ron). Also, the corresponding spelling languages are needed, e.g. aspell-de, aspell-fr, aspell-ro.
One issue in Linux is that the languages cannot be managed from within GImageReader, but only by installing or removing the above mentioned language packages. If no tesseract-ocr-* package is found, a confusing error is displayed:
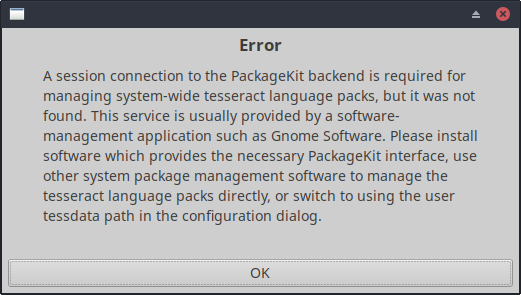
This is obviously crap, but it still confuses some people.
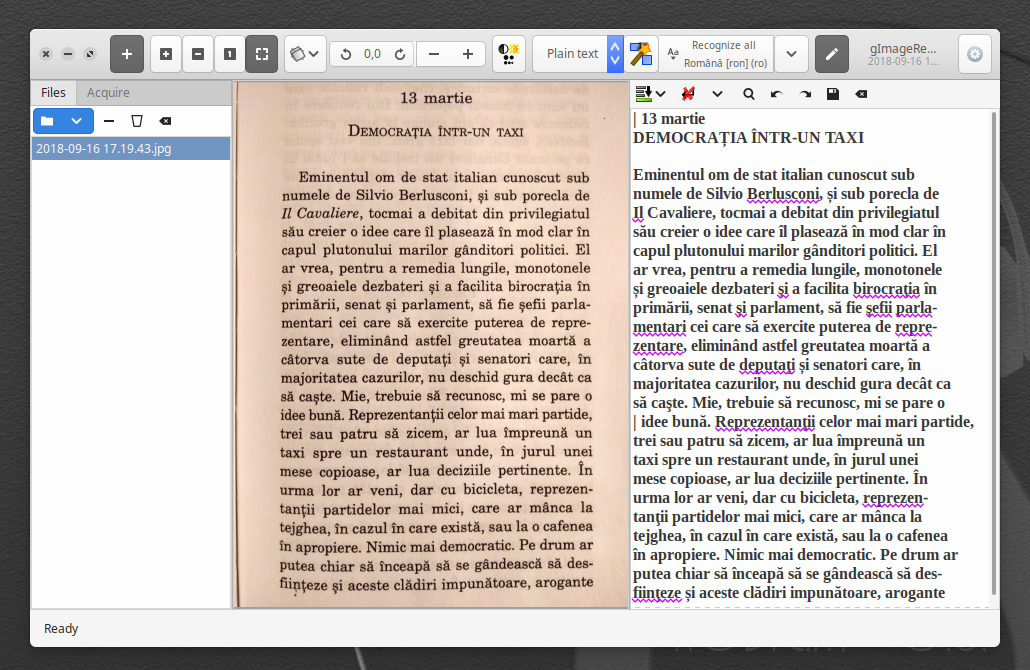
Other than that, it should work just fine once properly installed, should we ignore the “ţ/ț” and “ş/ș” annoyance:
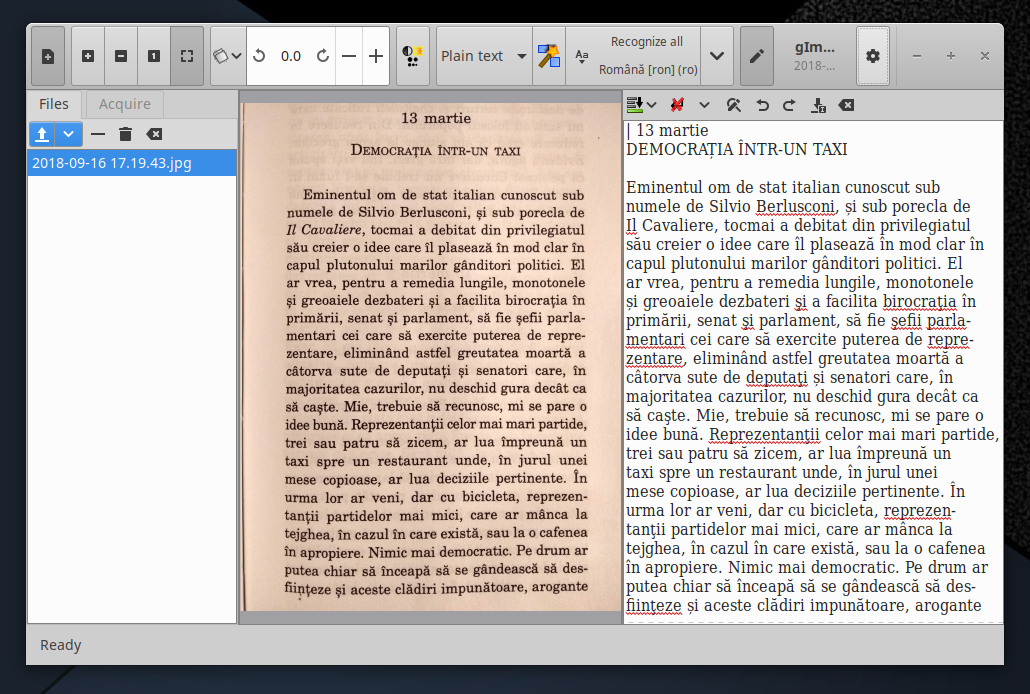
The skinning depends on the distro and of the desktop environment (and, as you noticed, there’s no caption bar):
Under Linux one could also use an older program, gocr (with gocr-tk for a GUI), which in turn uses cuneiform as OCR, but I’d advise against such a choice. It’s mostly abandoned. Some other tools of interest under Linux:
■pdfsandwich, a tool that generates “sandwich” OCR PDF files, i.e. PDF files that contain only images (no text) will be processed by OCR and the text will be added to each page invisibly “behind” the images. It uses tesseract.
■k2pdfopt, a PDF reflowing tool that optimizes multi-column PDF/DJVU files for mobile e-readers and smartphones. It can re-flow text even on scanned PDF files, and it too can create “sandwich” OCR files. Well, there’s also a Windows version of it, but I didn’t try it.
On the other hand, I never managed to get Lios (“Linux intelligent OCR solution”) do something. Anything.
I’ll end with a traditional meme for the French readers 🙂
