Google’s “nano-banana” & some Nvidia shit
I wasn’t aware of Gemini’s upgraded image editing capabilities based on Gemini 2.5 Flash Image (aka nano-banana), “our state-of-the-art image generation and editing model.” It was announced on their blog, with the version for Mideast & North Africa using “Nano Banana!” in the very title.
Bananarama cocktail
I couldn’t fucking care less. But on X I noticed a sort of hijacking. Higgsfield AI™ started offering Nano Banana, with unlimited free generations for the day of August 27.
A guy from Singapore who claims to be a film director & AI consultant, and also “partner with” some retards from Paris (but whose SSL certificate for has expired on February 26), has posted a couple of threads meant to scare the shit out of us. He praised “Higgsfield Swap-to-Video” which, apparently, can use “Nano Banana” in conjunction with Veo 3 and Kling 2.1 to create, well, deep fakes. Higgsfield’s “nano-bananized” shit (supposing they didn’t just steal the name and used it for a different product) can also replace voices in films and animations.
Here’s some of the crap he showed us (the first set of 7 is without sound, then the next set of 6 is about the sound):
Now, let’s get vocal! (3 of them have a lower audio volume than normal)
The lip sync stuff is actually using lipsync-2-pro. But when you combine enough such shit, the result is… a nightmarish world. And there are gazillions of startups who want to take everyone’s money (and minds), not just Higgsfield, which is a GenAI video platform that merely integrates 3rd-party AI tools.
Nvidia’s magic Synchrophasotron
If this wasn’t enough, I’ve learned about another madness, also via a thread on X. I’ll only quote from the first tweet:
NVIDIA research just made LLMs 53x faster. 🤯
Imagine slashing your AI inference budget by 98%.
This breakthrough doesn’t require training a new model from scratch; it upgrades your existing ones for hyper-speed while matching or beating SOTA accuracy.
Here’s how it works:
The technique is called Post Neural Architecture Search (PostNAS). It’s a revolutionary process for retrofitting pre-trained models.
Freeze the Knowledge: It starts with a powerful model (like Qwen2.5) and locks down its core MLP layers, preserving its intelligence.
Surgical Replacement: It then uses a hardware-aware search to replace most of the slow, O(n²) full-attention layers with a new, hyper-efficient linear attention design called JetBlock.
Optimize for Throughput: The search keeps a few key full-attention layers in the exact positions needed for complex reasoning, creating a hybrid model optimized for speed on H100 GPUs.
The result is Jet-Nemotron: an AI delivering 2,885 tokens per second with top-tier model performance and a 47x smaller KV cache.
Why this matters to your AI strategy:
- Business Leaders: A 53x speedup translates to a ~98% cost reduction for inference at scale. This fundamentally changes the ROI calculation for deploying high-performance AI.
- Practitioners: This isn’t just for data centers. The massive efficiency gains and tiny memory footprint (154MB cache) make it possible to deploy SOTA-level models on memory-constrained and edge hardware.
- Researchers: PostNAS offers a new, capital-efficient paradigm. Instead of spending millions on pre-training, you can now innovate on architecture by modifying existing models, dramatically lowering the barrier to entry for creating novel, efficient LMs.
This shit by Nvidia looks like bollocks to me, as they claim both speed and accuracy, but it’s almost impossible to obtain such a speed gain without a degradation in accuracy!
But look, I’ve got some nice pics from the GitHub page for Jet-Nemotron: Efficient Language Model with Post Neural Architecture Search:
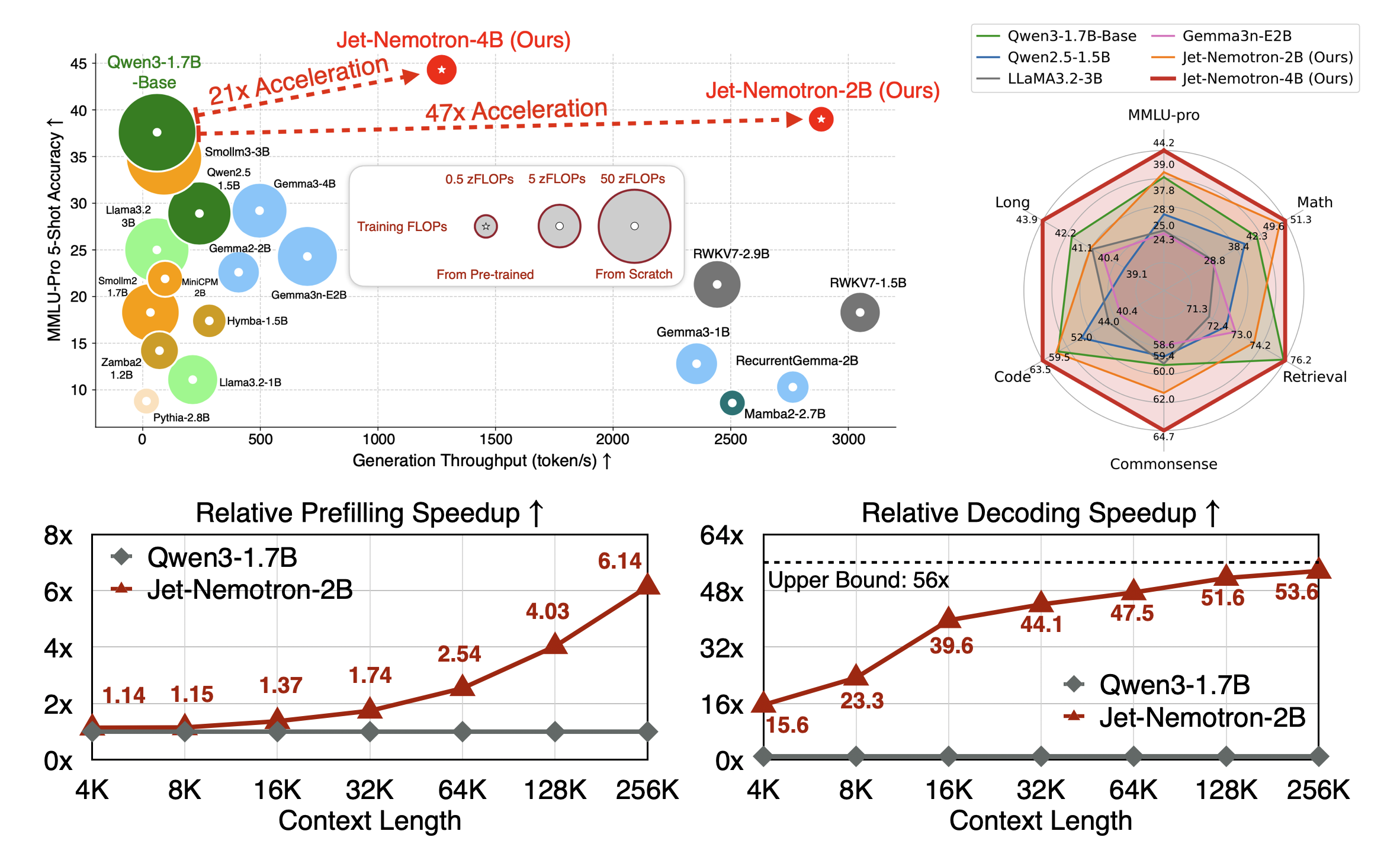
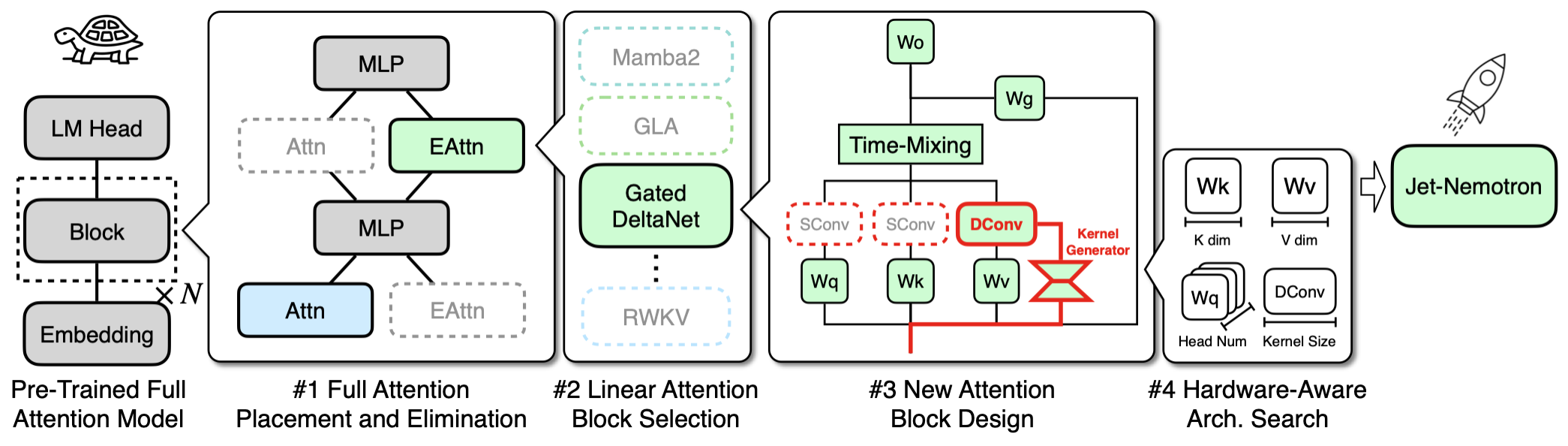
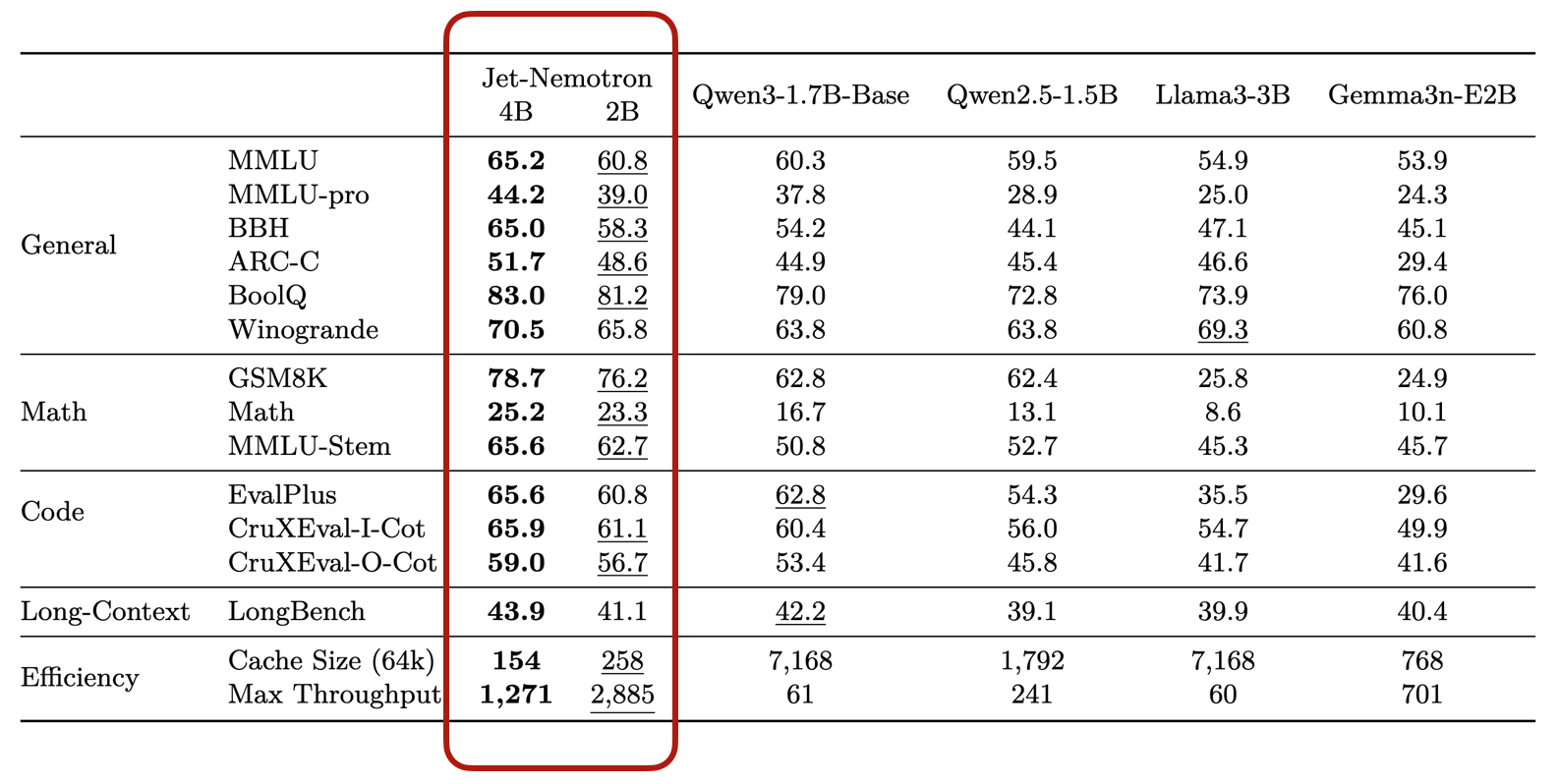
Many more details in the published study: arXiv:2508.15884v1 (I recommend the PDF).
LLMs as a universal solution is the wrongest way to use AI.
It all makes your head hurt. But who thought a name like nano-banana was the way to go? Ditto for Nemotron. He looks like a monster from a science fiction movie. Well, it kind of is… 🙂