My chatbot use in the last week
In the last seven days, I needed to use several chatbots for personal reasons (no coding or anything) slightly more intensively than usual, and I was curious with regard to which chatbot I’ve been using and how much. These quick numbers aren’t that relevant for several reasons, such as:
- I kept using Claude only for answers that needed rather simple answers, not complex analysis with nested lists, tables, and long threads with many follow-ups.
- For complex issues, including, e.g., medical and nutritional topics, I relied on GPT-5 in both Copilot and ChatGPT, then also Grok and Qwen3 (I wanted to test the new Qwen3-Max-Preview, and I found it quite good). So bear in mind that in most cases, the interactions (initial questions plus follow-ups) with these chatbots resulted in long answers.
- For synthesis of web searches, but also for some topics of moderate complexity, I used Kimi K2.
- The use of the other chatbots listed below was purely for the sake of variation, or because I judged them appropriate for the respective specific cases.
So it’s more like “apples and oranges” or maybe eggplants and bananas, so to speak.
| Chatbot | Interactions | Threads |
|---|---|---|
| Copilot (GPT-5) | 67 | 15 |
| ChatGPT (GPT-5) | 35 | 10 |
| Claude | 53 | 28 |
| Grok | 24 | 9 |
| Qwen | 20 | 3 |
| Kimi | 11 | 5 |
| Gemini | 4 | 3 |
| DeepSeek | 4 | 2 |
| Lumo | 4 | 2 |
| Total | 222 | 77 |
Grouping the first two chatbots under the same LLM, albeit differently configured by them, which is GPT-5:
| LLM | Interactions | % |
|---|---|---|
| GPT-5 | 102 | 45.9 |
| Claude Sonnet 4 | 53 | 23.9 |
| Grok 3 | 24 | 10.8 |
| Qwen3-Max-Preview | 20 | 9.0 |
| Kimi K2-0905 | 11 | 5.0 |
| Gemini 2.5 Pro | 4 | 1.8 |
| DeepSeek-V3.1 | 4 | 1.8 |
| Unknown (Lumo) | 4 | 1.8 |
A quick chart for the interactions, based on the first table:
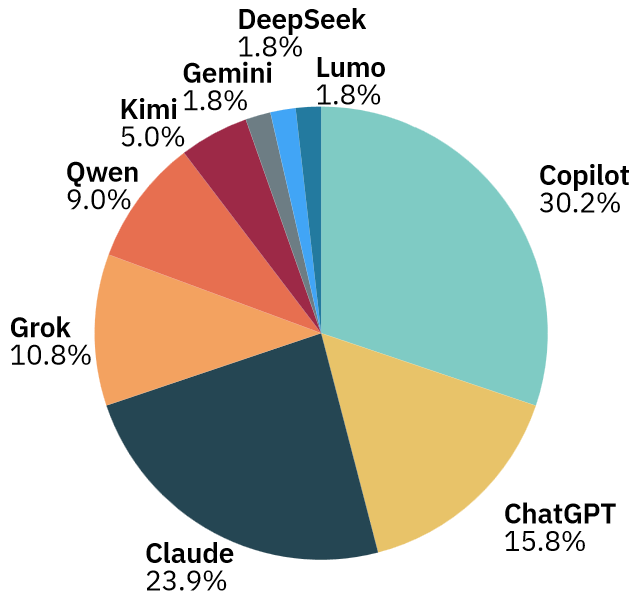
I had the feeling that I used Claude much less, but this might be due to the fact that it was “a quick fix” that I even forgot I’ve used. I also didn’t realize that I used Grok slightly more than Qwen, most likely because Grok was meant as a second opinion to GPT-5, and also because Qwen gave me very long but useful answers (à la ChatGPT). But I definitely hated when on occasions Grok kept repeating (with minor variations) entire paragraphs from previous answers in the same thread. Grok 3 is so passé, but it’s the only free one.
● I prefer GPT-5 in Copilot than in ChatGPT because of the more generous limits.
GPT-5 in ChatGPT
And yet, sometimes I was limited after as few as 5 messages!
GPT-5 in Copilot
Microsoft offers more flexible access to GPT-5 in Smart mode, but it’s not clearly defined. Copilot allows up to 5 Thinking interactions per day, and standard GPT-5 messages have no clearly announced limit, but they are not completely unlimited either. Microsoft seems to apply a dynamic calibration based on system load.
I have the experience of 20+ “GPT-5 (Smart)” answers in rapid sequence in the same thread, without triggering any limit!
● I noticed that Claude has changed the fonts in the Web UI (but not in the mobile app yet). From Reddit: New vs. old Claude UI fonts: The old fonts were Styrene B and Tiempos Text; the new fonts are “anthropicSans” (Anthropic Sans Text Light) and “anthropicSerif” (Anthropic Serif Text Light). They’re visibly thinner.
I would single out this comment: “I like the new font. In code, I don’t like the != changing to the = with a slash through it.”
That’s because they also replaced whatever fixed font they were using with “jetbrains” (JetBrains Mono Regular). Some developers love it (but I don’t, because I prefer the traditional !=).
● If Claude seemed a bit stupid 2-3 weeks ago, here’s why. Anthropic, on Sept. 17: A postmortem of three recent issues: “This is a technical report on three bugs that intermittently degraded responses from Claude. Below we explain what happened, why it took time to fix, and what we’re changing.”
● OpenAI says models are programmed to make stuff up instead of admitting ignorance (see the study: Why Language Models Hallucinate)
Regarding the last point, from a purely technical standpoint:
1) The model is not programmed to do what you tell it.
2) The model is not programmed to return data consistent with reality or truth, given that it doesn’t know what truth is and cannot evaluate it.
3) The model does not understand a single word of your prompt, the data it was trained on, or its own response.
4) The model is programmed to produce the most plausible (from a probabilistic perspective) continuation to your prompt, based on the data it was trained on. It’s just a language tool, not a reality tool.
5) Hallucinations are not errors, but correct (plausible) results of the algorithm functioning within normal parameters.
See my comments starting from here.
Grok 3 is not the only free one. Grok 4 is freely available from at least august.
Now you have Grok 4 Fast (beta), and I think Expert (Thinks hard) is basically Grok 4 normal, but you can also explicitly select it right at the bottom, from Models.
Absolutely, except that your image doesn’t work because this comments system bans WEBP. Why don’t you use PNG?
And Grok 4 was made available later, but you couldn’t be fucking bothered to check my later posts.
I’ll check your posts regarding AI from the beginning. But this is relatively new, from last month.
I used Grok 4 in August (see the link), so it existed in August. Maybe you spotted it later?
Indeed, I failed to notice it right away.
But yes, it is a good idea to check your later posts. 🙂 So this is on me.